
С LLaMa и Alpaca вы можете использовать чат-бота, такого как ChatGPT, локально, больше не завися от облака.

в машинное обучение обучение и логический вывод являются двумя основными этапами в процессе разработки модели.
Л’обучение это этап, на котором модель обучается на наборе данных, как правило, очень большом, чтобы оптимизировать возможности искусственного интеллекта и правильность предоставляемых ответов. На этом этапе модель использует алгоритм обучения, чтобы попытаться найти взаимосвязь между характеристиками входных данных и «подходящей» информацией, которая будет предложена на выходе. В процессе обучения модель старается минимизироватьошибка предсказания на данных обучения и улучшить его производительность. Обучение может занять много итераций, во время которых модель обновляется новыми данными, чтобы улучшить себя.
Фаза обучения обычно требует много времени и огромных (и дорогих) аппаратных ресурсов: только подумайте, чтобы добраться до Генеративная модель GPT-3OpenAI использовал бы более 250 000 ядер ЦП, более 10 000 ядер NVidia (GPU) и межсоединение со скоростью 400 Гбит/с.
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)
Л’выводвместо этого является следующей фазой, на которой модель используется для прогнозирования новых данных: модель получает входные данные, которые она, возможно, никогда раньше не видела, по крайней мере, не в той форме, в которой она использовалась, и использует вероятностный подход для генерации выходных данных. на основе информации, полученной в ходе обучения.
Короче говоря, модель предлагает ответ на основевход предоставил. Например, можно спросить, представляет ли изображение, отправленное в качестве входных данных, кошку или нет; транскрибировать аудио в текст (speech-to-text); для создания текста для ответа на вопрос или завершения размышления пользователя (это то, что делают ChatGPT, Bing Chat и Google Bard) или для создания новых изображений, исходя из текстовых описаний.
Фаза вывода – это деятельность, которая по определению многопользовательский: набор «запросов» одновременно отправляется в качестве входных данных для модели с использованием нескольких экземпляров самой модели, предварительно обученных.
На этом этапе также требуется массивная аппаратная конфигурация, способная «масштабироваться» вверх, когда число и сложность входных запросов быстро растут.
Недавно президент Alphabet, «материнской компании» Google, подсчитал, что чат-боты, основанные на искусственном интеллекте, стоят в 10 раз больше, чем обычный поиск в традиционных системах (вспомните веб-поиск в Google…).
В генеративных моделях или моделях естественного языка мы говорим о миллиарды параметров которые соответствуют количеству «весов», используемых для обучения модели (ChatGPT основан на модели, обученной с использованием более 175 миллиардов параметров).
В нейронная сетьвеса — это значения, которые модель пытается оптимизировать, чтобы найти взаимосвязь между входными данными и желаемыми выходными данными.
В контексте генеративных моделей часто требуется очень большое количество параметров для создания полного и подробного представления объекта. входные данные; в модель естественного языка обычно требуются миллиарды параметров для точного представления синтаксической и семантической структуры языка.
Что такое большие языковые модели (LLM)
Модели большого языка (LLM) — это модели естественного языка, которые используют искусственные нейронные сети с очень большим количеством параметров для создания представление естественного языка мощный, актуальный и сложный.
Эти шаблоны способны понимать и генерировать текст высокого качества, а не только на основе семантика и к синтаксисно и к нюансам естественного языка.
Среди наиболее известных примеров LLM — различные версии модель GPT (Generative Pre-trained Transformer), разработанный OpenAI: в другой статье мы видели, как создать генеративную модель, такую как GPT, в 60 строках кода Python.
лама и альпака
Однако помимо простых упражнений мы хотим поговорить о паре инструментов, которые действительно можно использовать для практическое применение внутри ИИ без привязки к облаку и любому стороннему поставщику.
Мета (Facebook) создана ЛЛаМа (мета AI модели большого языка): как объяснено в страница презентации, это набор моделей, использующих от 7 до 65 миллиардов параметров. При использовании «облегченного» подхода (LLaMa весит в 10 раз меньше, чем OpenAI GPT-3), согласно Meta, модель способна дать отличные результаты.
Общедоступная реализация LLaMa на GitHub проста в использовании, ее также можно использовать на обычных компьютерах, а также можно запускать непосредственно на ЦП без необходимости использования мощных графических процессоров последнего поколения.
Пер уменьшить нагрузкуиспользуется так называемое 4-битное квантование.
4-битное квантование это метод, который уменьшает количество битов, используемых для представления данных, за счет снижения занимаемой памяти и вычислительных затрат.
В этом указанном случае только 4 бита используются для представления каждого числового значения в векторе данных. Это означает, например, что вместо использования 32-битный форматкоторый требует в четыре раза больше памяти, представление данных значительно сжимается.
Надо сказать, что при снижении количество бит в целом наблюдается меньшая точность модели и гораздо большая содержательная способность к обобщению.
В середине марта 2023 года группа исследователей из Стэнфордского университета, играя на аббревиатуре LLaMa, представила Альпака.
Альпака представляет собой оптимизированную версию модели LLaMa с 7 миллиардами параметров: несмотря на то, что она очень легкая и дешевая в управлении, Alpaca демонстрирует поведение, качественно аналогичное текст-davinci-003 на OpenAI.
Чтобы дать представление о том, как Alpaca делает использование современных генеративных моделей действительно доступным для всех, просто подумайте, что реализация, которую мы собираемся представить, также может работать на обычном ПК с 16 ГБ оперативной памяти с современным процессором на 6 или 8 физических ядер.
Очевидно, что по мере увеличения количества параметров требования ужесточаются (например, для запуска модели с 30 миллиардами параметров требуется 32 ГБ ОЗУ), но это технические характеристики оборудования решительно далеки от необходимости иметь суперкомпьютер.
Как использовать генеративную модель на локальном компьютере
Предполагая, что у вас есть машина Убунту Линукс тестов с оперативной памятью не менее 16 ГБ, вы можете протестировать Alpaca, выполнив следующие команды. Различные инструкции позволяют вам установить Docker и загрузить генеративную модель внутри контейнер:
обновление sudo apt && обновление sudo apt -y
sudo apt установить apt-transport-https curl gnupg-agent ca-certificates software-properties-common -y
завиток -fsSL | sudo gpg –dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
эхо “деб” [arch=$(dpkg –print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] $(lsb_release -cs) стабильный” | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
обновление sudo apt && обновление sudo apt -y
sudo apt установить docker-ce -y
Команда sudo systemctl status docker позволяет проверить, действительно ли Docker установлен и работает.
Выполнение следующей команды устанавливает программное обеспечение Сержупрощенный инструмент для общения с Альпакой, LLaMa и другими моделями – открытый исходный код доступно на GitHub и свободно используется:
Серж прослушивает TCP-порт 8008: предполагается, что используется брандмауэр ufw, поэтому необходимо Открой дверь в подъезде:
Введя IP-адрес Linux-машины, а затем :8008, вы получите доступ к домашней странице Сержа.
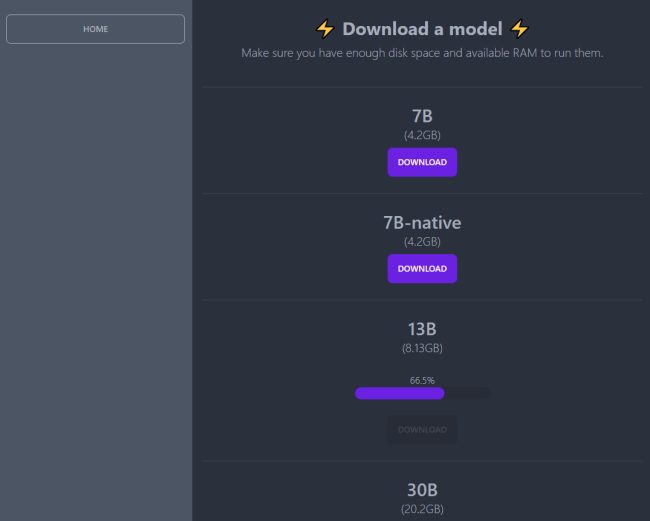
Нажав «Загрузить модели», вы можете сначала загрузить предпочтительную модель, в зависимости от количества параметров, используемых на этапе обучения.
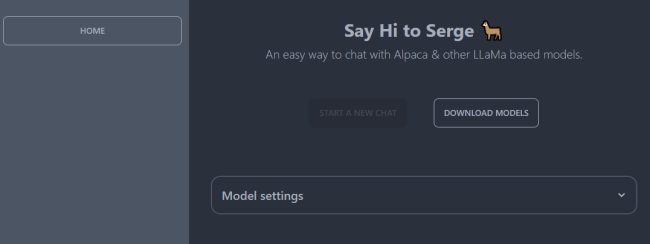
Поэтому, нажав «Главная», мы предлагаем выбрать «Настройки модели», чтобы настроить поведение модели:
- Температура. Определите, насколько свободен ответ ИИ. Меньшие числа приводят к более жестким ответам, в то время как более высокие числа вызывают больше творчества.
- Максимальная длина генерируемого текста в токенах. Максимальная длина текста, генерируемого в токенах, или длина ответов, написанных чат-ботом.
- Выбор модели. Позволяет выбрать модель с 7, 13 или 30 миллиардами параметров среди загруженных локально.
- n_threads. Количество потоков, которые Серж/Альпака может использовать на уровне ЦП. Выделение больше, чем по умолчанию 4, очевидно, значительно повышает производительность.
- Предварительная подсказка для инициализации разговора. Предоставляет контекст до начала разговора, чтобы повлиять на реакцию чат-бота.
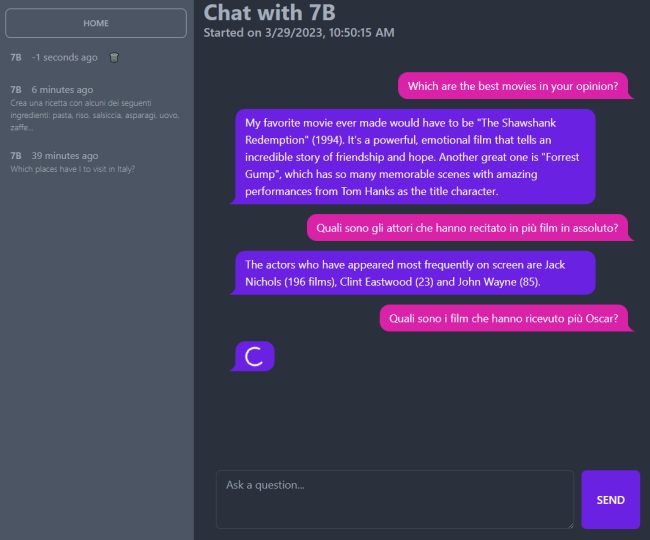
На данный момент система показывает, что она также понимает i вопросы на итальянском языке но он отвечает только на английском.
Ландшафт постоянно меняется, поэтому вскоре можно будет получать ответы и на итальянском языке. Важно отметить, что потенциал подхода, подобного представленному: загрузка всей генеративной модели локально и ее бесплатное использование из облака и от любой третьей стороны бесценны, особенно с точки зрения разработчиков и системных интеграторов.
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)





