
Возникли проблемы с копированием текста из PDF-файла? Вот как решить эту проблему без особых усилий

Документы в PDF-формат они также часто используются как простые «контейнеры» изображений, полученных с помощью сканер. Многие приложения позволяют создавать многостраничные PDF-файлы: каждая страница соответствует листу бумаги, предварительно отсканированному в цифровом виде. Однако зачастую при этом возникают значительные трудности. скопировать текст из PDF.
Если вы не можете открыть PDF-документ выбирать и скопировать текст в другом месте (CTRL+C, CTRL+V) обычно означает, что в файле есть только изображения. Запишите любое слово, которое встречается в файле, затем нажмите комбинацию клавиш CTRL+F. Если, набрав одно и то же слово в поисковая строкавы не получили ни одного совпадения (нулевые результаты), вы получите дополнительное подтверждение отсутствия текста, доступного для поиска, в PDF-документе.
Как распознать текст в PDF-документе с помощью OCR
Существует множество решений проблемы необходимости поиска или копирования текста из документа. Отсканированный PDF-файл. Одним из лучших, простых в использовании и нулевых затрат является использование приложения с открытым исходным кодом. OCRmyPDF.
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)
Это инструмент, предназначенный для добавления слоя текста в файлы PDF, содержащие только изображения, с использованием функции оптическое распознавание текста (оптическое распознавание символов).
OCRmyPDF — мощный и гибкий инструмент, который решает одну из распространенных проблем, связанных с PDF-файлами, созданными из отсканированные документы. Его основная функция — создание файла PDF/A с возможностью поиска из обычного PDF-файла, что позволяет пользователям проводить поиски в документе, а также копирование и вставка текста в другие контексты.
Программное обеспечение OCRmyPDF точно позиционирует распознанный текст ниже исходного изображения, что упрощает операцию скопировать и вставить. Он также сохраняет точное разрешение изображений, встроенных в исходный документ, и может по запросу исправитьнаклон изображений (исправление перекоса) перед выполнением операции оптического распознавания символов.
OCRmyPDF также позволяет вам оптимизировать PDF-изображениячасто создавая файлы меньшего размера, чем входной документ.
С точки зрения производительность, приложение эффективно распределяет работу по обработке PDF-файлов, распределяя задачи между всеми доступными ядрами ЦП. Таким образом, OCRmyPDF может сократить время управления большими документами, состоящими из большого количества страниц (мы проверили, что результаты превосходны даже с документами, состоящими из тысяч страниц).
Шаги по установке OCRmyPDF
Такое программное обеспечение, как OCRmyPDF, зародилось как приложение, предназначенное в первую очередь для систем GNU/Linux. Тем не менее, это очень простая в использовании утилита. Windows 10 е в Windows 11.
Программа не имеет графического интерфейса и работает исключительно из командная строка. Несмотря на это, все остается действительно простым и доступным для любого пользователя.
Ниже приведен список команд, которые можно использовать на различных Дистрибутивы Linux установить OCRmyPDF с различными менеджер пакетов доступный:
Операционная система Команда установки Debian, Ubuntu apt install ocrmypdf Подсистема Windows для Linux apt install ocrmypdf Fedora dnf install ocrmypdf macOS (Homebrew) Brew install ocrmypdf macOS (nix) nix-env -i ocrmypdf LinuxBrew Brew install ocrmypdf FreeBSD pkg install py-ocrmypdf Conda conda установить ocrmypdf Ubuntu Snap snap установить ocrmypdf
В таблице вы также увидите указанные Подсистема Windows для Linux (WSL): да, потому что, например, установив Ubuntu в Windows 10 и Windows 11, а затем запустив ее в окне с WSL, вы все равно сможете распознать содержимое PDF и получить новый файл.
Как использовать OCRmyPDF в Windows с WSL
Предполагая, что вы используете Linux в Windows с WSL и уже успешно установили Убунту 22.04 (wsl –install -d Ubuntu-22.04 в командной строке, открытой с правами администратора), вы можете установить OCRmyPDF с помощью одного оператора:
sudo apt install ocrmypdf -y
На этом этапе все готово: нажав Windows+R, затем набрав \\WSL$ и нажав Enter, вы получите доступ к файловая система из Убунту. Двойным щелчком по ресурсу Ubuntu-22.04, затем по домашней папке и, наконец, по имени пользователя, настроенному в Linux, вы можете скопировать PDF-файл для обработки (тот, который содержит сканы с бумажных страниц).
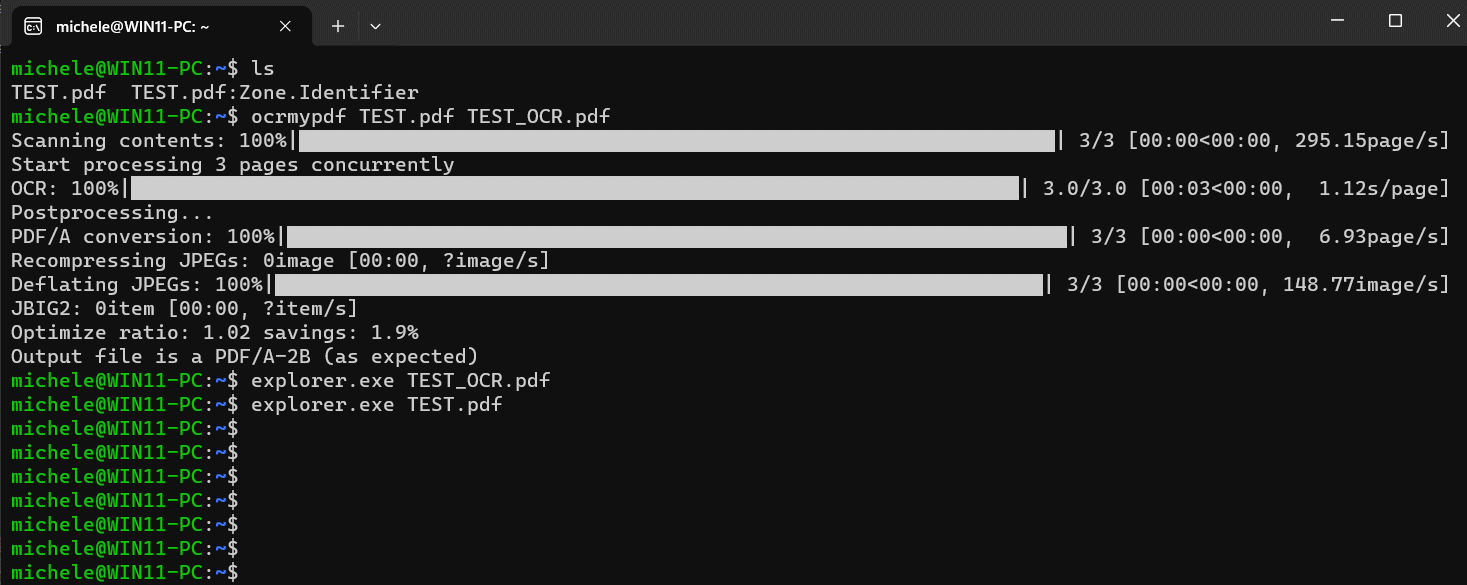
Затем в окне WSL вы можете ввести следующую команду:
ocrmypdf input.pdf вывод.pdf
Вместо input.pdf необходимо указать имя оригинального PDF-файла, только что скопированного в файловую систему Ubuntu. Вместо этого строку output.pdf следует заменить именем документа, который вы хотите получить. Также возможно добавление опции –skip-text, OCRmyPDF. игнорировать страницы которые уже содержат текст, вместо этого основное внимание уделяется тем, которые содержат только изображения. Опция полезна для всех тех, кто «смешанные» документы которые сочетают в себе контент, созданный в цифровом формате, и копии напечатанных страниц, снятые сканером или фотографией.
Он также подходит для «нормализовать» в PDF-файле конвертировать их в формате PDF/A, независимо от их типа и содержимого, которое они размещают:
ocrmypdf –skip-text input.pdf вывод.pdf
Следующая команда выполняет распознавание текста для указанного входного PDF-файла, создает новый PDF-файл с распознаванием английского и итальянского языков, исправляя любые ошибки. несовершенные наклоны изображений (что довольно часто встречается при сканировании страниц):
ocrmypdf input.pdf output.pdf –language eng+ita –deskew
OCRmyPDF представляет собой незаменимый инструмент для всех, кто работает с документами, отсканированными в формат PDF. Благодаря своим многочисленным функциям и способности управлять большими объемами страниц он делает возможным немедленное выделение текста и последующее копирование и вставку.
Файл output.pdf, созданный в домашней папке пользователя Ubuntu, можно легко скопировать в другое место, используя Проводник файлов.
Узнать больше о синтаксис расширенные версии OCRmyPDF доступны в Кулинарная книгас которым мы приглашаем вас ознакомиться.
Вступительное изображение предоставлено: iStock.com – Монтичелло
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)





