
Как объяснить функционирование языковой модели LLM без использования математики (или почти)
/https://www.ilsoftware.it/app/uploads/2024/05/funzionamento-LLM-IA.jpg "Как объяснить функционирование языковой модели LLM без использования математики (или почти)")
На всех уровнях много говорят о генеративном искусственном интеллекте и термине лингвистические модели Это сейчас у всех на слуху. ТО Большие языковые модели (Магистр права) — это высокопроизводительные языковые модели, предназначенные для понимания и генерации текста так же, как это сделал бы реальный человек. Они способны выполнять широкий спектр лингвистических задач, таких как машинный перевод, генерация текста, ответы на вопросы, создание резюме и многое другое. Они могут «понять» контекст и составить связный текст и значимы в ответ на вопросы или ввод естественного языка.
В наших статьях мы обычно заключаем глагол «понимать» в кавычки, потому что LLM, очевидно, не может полагаться на те же механизмы, которые лежат в основе человеческого мозга. Они пытаются приблизить его функционирование, иногда весьма блестяще, в других случаях менее эффективно. Но мы всегда говорим о приближении.
Чем занимается LLM (Большая языковая модель)
Как мы подчеркивали в других исследованиях, многие пользователи не совсем понимают функционирование LLM. За их режим работы там много математики и статистики: по этой причине это считается сложным.
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)
В основе LLM лежит концепция жетон: часто накладываются на отдельные слова и фактически могут представлять собой последовательность символов или несколько слов (или их частей). Токен также может выражать точку или пробел: фактически цель каждого LLM состоит в том, чтобы закодировать текст максимально эффективным способом.
Каждому токену, присутствующему в словарный запас специфично для конкретного LLM, ему присваивается уникальный числовой идентификатор. LLM использует токенизатор (переводится на итальянский как «токенизатор«), чтобы преобразовать текст в эквивалентную числовую последовательность. Эти числовые представления являются именно токенами.
Практический пример с Python
Код Python, который мы предлагаем ниже, использует библиотеку tiktoken для кодирования и декодирования текстов с помощью Модель ГПТ-2. Это самая простая модель, которую OpenAI выпустила как продукт с открытым исходным кодом, поэтому ее можно изучить подробно. В другой статье мы увидели, как использовать электронные таблицы и GPT-2, чтобы продемонстрировать, как работают LLM.
После импорта модуля код кодирует данное предложение, используя модель GPT-2, с помощью функцииcoding_for_model(). Видите ли вы числа, возвращаемые для каждого токена? Здесь, проведя операцию декодирования, можно получить исходное предложение.
>>> import tiktoken >>>coding = tiktoken.encoding_for_model(“gpt-2”) >>>coding.encode(“Il gatto nero attraversa la strada buia.”) (33666, 308, 45807, 299, 3529, 708 , 430, 690, 64, 8591, 965, 4763, 809, 544, 13) >>> кодирование.декодировать((33666, 308, 45807, 299, 3529, 708, 430, 690, 64, 8591, 965, 4763 , 809, 544, 13)) 'Il gatto nero attraversa la strada buia.'
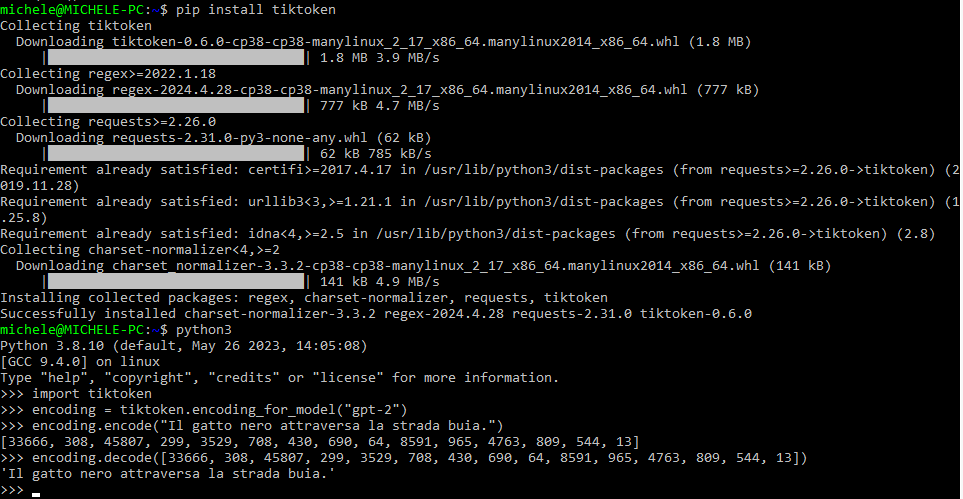
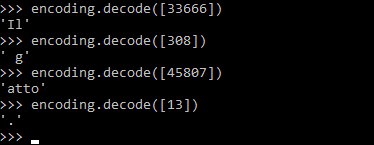
Интересно, что, как мы упоминали ранее, токен не обязательно содержит слово. Например, `(308)` декодируется как 'g' (начало слова “кошка” с пробелом в начале), `(45807)` как `act', а `(13)` как точка. Посмотрите на результат, полученный на рисунке, вызвав функциюcoding.decode:
Имейте в виду, что библиотека tiktoken, вызываемая через Python, обязательно должна быть установлена с помощью команды pip install tiktoken.
Языковые модели делают прогнозы
Давайте вернемся к утверждению, с которого мы начали: говоря о навыках «понимания» студентов-магистров права, мы заключаем этот термин в кавычки. Поскольку подход, используемый этими системами, по сути, вероятностный. Или еще лучше, как мы говорили в статье о генеративных моделях на службе бизнес-решений, используемая схема относится к схеме первого типа. стохастический.
Языковые модели делают прогнозы какой токен будет следовать за обрабатываемым. Представьте себе функцию, которая возвращает вероятность того, что каждый термин, содержащийся в словаре модели, может следовать за определенным токеном.
Поскольку Словарь GPT-2 основана на использовании 50.257, функция (разработанная, например, на Python) будет предоставлять список чисел, указывающих вероятность, с которой соответствующий токен может следовать после одного рассматриваемого слова.
В случае с примером «Черная кошка переходит темную улицу«, можно предположить, что, например, слово типа «тунец» имеет почти нулевую вероятность следовать в предложении. Скорее всего, оно может следовать за союзом типа «и». «Черная кошка переходит темную дорогу и прячется в живой изгороди.«. Или, опять же: «и его сбивают” о “и прыгает в канаву“или еще раз”и садится в такси(конечно, менее вероятно…).
Разумные прогнозы основаны на осторожности. этап обучения модели. В модель передаются объемы текста, зачастую впечатляющие по размеру. Таким образом, он может понять смысловые ссылки между словами языка всегда и только в вероятностных терминах.
В конце обучения модель может рассчитать вероятности, с которыми каждый токен может встречаться в различных предложениях, в зависимости от уже присутствующих последовательностей токенов, на основе структур данных, построенных с использованием всего текста, обработанного на этапе обучения.
Генерация длинных текстовых последовательностей
Во многих статьях мы говорили, что создать хорошо продуманную подсказку это ключ к получению аргументированных, контекстуальных и актуальных ответов от LLM.
Представьте себе гипотетическую функцию Python, которая принимает на вход предложение, введенное пользователем (теперь быстрый). Прежде всего, модель делает следующее: токениззаре иль быстрый затем сгенерируйте последовательность уникальных числовых значений (мы видели это раньше с кодированием.encode).
На данный момент, в зависимости от длина текста что ты хочешь войти выход, делает серию прогнозов о токенах, которые с наибольшей вероятностью завершат входную последовательность токенов. Вы заметили, как LLM повторно использует большую часть введенных пользователем данных при составлении ответа?
Функция Python, о которой мы говорим, может просто выбирать токены с помощью более высокая вероятность следовать за другим токеном. По-английски этот подход называется жадный выбор. Однако, используя генератор псевдослучайных чисел, можно сделать механизм более «динамичным»: вместо того, чтобы всегда выбирать наиболее вероятные токены, можно случайным образом выбрать один из тех, которые — с точки зрения вероятности — превышают определенную величину. Порог.
Теперь вы понимаете, почему, предоставляя то же самое быстрый к генеративной модели в несколько разных моментов времени это обычно дает ответы, которые иногда сильно отличаются друг от друга.
Температура в ЛЛМ
В контексте LLM, температура это параметр, используемый при создании текста, который определяет, насколько «креативным» или «консервативным» должен быть текст.выход.
Более конкретно, температура регулирует распределение вероятностей слов, сгенерированных моделью. При более высокой температуре модель с большей вероятностью будет производить творческие результаты и удивительно, поскольку вероятность распределяется между разными словами в его словаре более равномерно. Напротив, при более низкой температуре модель дает более консервативные и последовательные результаты, поскольку она опирается на наиболее вероятные слова абсолютно (понятие жадный выбор).
В расширенных настройках некоторых LLM вы могли встретить упоминания о так называемом гиперпараметры top_p и top_k: контролируйте, сколько наиболее вероятных токенов будут рассматриваться для выбора.
Как только токен выбран с помощью описанного выше подхода, цикл повторяется. Поэтому описанная ранее функция вызывается снова путем передачи входных данных, обогащенных новым токеном. При этом генерируется следующий токен, следующий за только что поставленным в очередь, и так далее. Процесс продолжается.
В LLM нет концепции предложений и абзацев, потому что, как мы видели, они работают с одним токеном за раз. Чтобы предотвратить обрезание сгенерированного текста в середине предложения, можно установить код разорвать порочный круг когда генерируется токен, соответствующий точке.
Как работает обучение LLM
Максимально упрощая, предположим, что мы используем LLM, в котором используется словарь, состоящий всего из 8 слов на итальянском языке: «il», «собака», «кошка», «есть», «пить», «молоко», « мясо», «хлеб».
Предположим, что каждому слову соответствует один токен. Предположим также, что у нас есть набор только из 3 обучающие предложения:
«Собака ест мясо»
«Кошка пьет молоко»
«Собака ест хлеб»
Модель LLM учится прогнозировать вероятность каждого токена в зависимости от контекста обучающих предложений. Затем создайте таблицу, в данном случае 8х8, в которой будут подсчитываться появления токенов. В частности, LLM записывает в каждой ячейке, сколько раз за токеном, указанным в каждой строке, следует токен, указанный в заголовке столбца. Имейте в виду, что, опять же для простоты, мы не делаем разницы между «Il» (с большой буквы) и «il» (с маленькой буквы).
собака кот ест пьет молоко мясо хлеб на 0 2 1 0 0 0 0 1 собака 0 0 0 2 0 0 0 0 кот 0 0 0 0 1 0 0 0 ест 1 0 0 0 0 0 1 0 пьет 1 0 0 0 0 0 0 0 молоко 0 0 0 0 0 0 0 0 мясо 0 0 0 0 0 0 0 0 хлеб 0 0 0 0 0 0 0 0
Эти события, полученные на основе обучающих данных, очевидно, можно преобразовать в вероятности. Вероятность того, что токен следует за другим токеном в предложении.
Размер контекстного окна
Проблема с этим подходом, сказал Цепь Маркова, заключается в том, что он учитывает только последний токен ввода. Любой текст, который появляется перед последним обработанным токеном, не влияет на выбор последующих токенов. Так называемое контекстное окно (контекстное окно), следовательно, в этом отношении равен одному токену.
Такой подход практически бесполезен, поскольку модель перескакивает от одного слова к другому, выбирая новые токены, не имея при этом никаких жетон «память» деи ранее обработанный. Результат очевиден: контексте быстрый его невозможно сохранить никаким образом.
Поэтому для улучшения прогнозов необходимо построить таблица вероятностей больше по размеру. Предположим, вы используете контекстное окно, состоящее из токен причитающегося долга. Ограничиваясь 8 токенами, использованными в примере в предыдущем абзаце, в таблицу следует добавить 64 новых строки ниже уже имеющихся 8. Затем модель следует снова обучить.
Однако даже в контекстном окне с двумя токенами вновь добавленные токены не могут ссылаться на концепции и идеи, выраженные предыдущими токенами.
Устаревшая модель OpenAI GPT-2 с открытым исходным кодом использует контекстное окно 1024 жетона. Чтобы реализовать контекстное окно такого размера с использованием цепей Маркова, каждая строка таблицы вероятностей должна представлять собой последовательность от 1 до 1024 токенов.
Это означает, что если ограничиться ограниченным словарем из 8 токенов/слов, рассмотренным ранее, то получится 81024 возможных последовательностей по 1024 токенов длиной. Таким образом, строки таблицы, необходимые для представления всех возможных вероятностей, равны 81024:
5809605995369958062859502533304574370686975176362895236661486152287203730997110225737336044533118407251326157754980517443990529594540047121662885672187032401032111639706440498844049850989051627200244765807041812394729680540024104827976584369381522292361208779044769892743225751738076979568811309579125511333093243519553784816306381580161860200247492568448150242515304449577187604136428738580990172551573934146255830366405915000869643732053218566832545291107903722831634138599586406690325959725187447169059540805012310209639011750748760017095360734234945757416272994856013308616958529958304677637019181594088528345061285863898271763457294883546638879554311615446446330199254382340016292057090751175533888161918987295591531536698701292267685465517437915790823154844634780260102891718032495396075041899485513811126977307478969074857043710716150121315922024556759241239013152919710956468406379442914941614357107914462567329693696
Действительно сумасшедшая цифра! Если вы думаете, что с ГПТ-3контекстное окно довели до 2048 токенов, с GPT-3.5 до 4096 токенов и с GPT-4 мы достигли, при нескольких последующих “обновлениях”, что-то вроде 128 000 токенов, видно, что цепи Маркова – не лучший подход.
Кстати, более современные модели начинают использовать контекстные окна размером с более 1 миллиона токенов. Итак, подумайте о количестве строк таблицы, которое будет получено, если указать количество слов в словаре в качестве основы (a) и размер контекстного окна в качестве показателя степени (b): ab.
От таблиц вероятностей к нейронным сетям
Управление таблицей вероятностей такого размера, как описанные выше, особенно с моделями, характеризующимися особенно большими контекстными окнами, потребует большого количества усилий. Оперативная память впечатляющий. Тогда на помощь приходят нейронные сети.
А нейронная сеть его можно рассматривать как функцию, которая аппроксимирует вероятности различных токенов, используя более или менее большой набор параметров.
я параметры в нейронной сети, обслуживающей LLM, относится к информации, которую сама нейронная сеть изучает в процессе обучения. Эти параметры включают в себя гири связей между нейронами и предвзятость каждого нейрона в каждом слое сети.
Веса? Нейроны? Предвзятость? Слишком много понятий одновременно. Попробуем немного прояснить ситуацию.
Каковы параметры и веса связей между нейронами?
Мы сказали, что «параметры» относятся к внутренним переменным модели, изученным в процессе обучения. Это важная информация для определения поведения нейронной сети при обработке входных данных и генерации данных. выход.
Нейронные сети состоят из вычислительных блоков, называемых нейроны, организованные по слоям (подробнее об этом позже). Каждая связь между нейронами имеет соответствующий «вес», который указывает наважность связи. Во время обучения эти веса корректируются так, чтобы сеть могла научиться представлять сложные отношения, наблюдаемые во входных данных.
Помимо весов связей, каждый нейрон имеет связанное с ним «смещение». предвзятость представляет порог активации нейрона: если взвешенная сумма входных сигналов превышает значение смещения, нейрон активируется. Например, в нейронной сети для классификация текстовпредубеждения помогают определить, когда определенный нейрон должен сработать в ответ на определенные слова или лингвистические особенности.
GPT-2 имеет примерно 1,5 миллиарда параметров, а GPT-3 инженеры OpenAI довели это количество до 175 миллиардов параметров. В случае с GPT-4, несмотря на отсутствие официального подтверждения, количество параметров должно быть эквивалентно примерно 1,76 триллионам (1760 миллиардов).
В контексте LLM параметры имеют основополагающее значение для представления языковой модели и «знаний», полученных в ходе обучения. Например, веса соединений отражают смысловые отношения е синтаксис между словами, в то время как предубеждения, как уже упоминалось, влияют на активацию нейронов в процессе языковой обработки.
Оптимизировать процесс обучения нейронной сети
Процесс обучения нейронной сети состоит из определения параметров, необходимых для обеспечения наилучшей работы функции при оценке на данных, содержащихся в обучающем наборе. Если функция хорошо работает с обучающими данными, она также будет хорошо работать и с другими данными, например с данными, которые она никогда раньше не видела.
При обучении нейронной сети параметры настраиваются через алгоритм оптимизации. Одним из наиболее распространенных методов, используемых в этом отношении, является процесс обратное распространение ошибкикоторый можно разделить на несколько этапов:
- Пас вперед: на этом этапе входные данные передаются в нейронную сеть и рассчитываются прогнозы. Эти прогнозы сравниваются с целевыми значениями для расчета потерямера несоответствия между предсказаниями модели и ожидаемыми значениями.
- Обратный проход (обратное распространение ошибки): После расчета потерь алгоритм обратное распространение ошибки разработать и градиенты потерь. Они предоставляют информацию о том, как следует обновлять параметры сети, чтобы улучшить производительность модели. Если градиент по определенному параметру положителен, это означает, что увеличение параметра приведет к увеличению потерь, а если он отрицательный, это означает, что увеличение параметра приведет к уменьшению потерь.
- Обновление параметров: после расчета градиентов алгоритм оптимизации используется для обновления значений параметров. Обновление параметров обычно происходит на основе градиента функции потерь относительно самих параметров.
- Итерация: описанные выше шаги повторяются итеративно для всего набора обучающих данных. Цель состоит в том, чтобы постепенно уменьшить потери по всем обучающим данным, тем самым улучшая прогнозирующие возможности нейронной сети.
Слои, Трансформеры и внимание
Нейронная сеть настроена на выполнение цепочки операций, каждая из которых называется слой (о уровень). Первый слой принимает входные данные и выполняет над ними какое-то преобразование. Преобразованные входные данные передаются на следующий уровень и обрабатываются еще раз. Это продолжается до тех пор, пока данные не достигнут последнего слоя и не будут преобразованы в последний раз, генерируя выходные данные или прогноз.
Самая популярная сегодня архитектура нейронных сетей для генерации текста с помощью современных языковых моделей называется Transformer, представленная в 2017 году группой инженеров Google.
Отличительной особенностью LLM на основе Transformer является многоуровневая обработка, осуществляемая с использованием механизма внимания. Главный герой еще одной нашей статьи,Внимание это позволяет выводить отношения е модели среди токенов, присутствующих в контекстном окне, что отражается – в вероятностном выражении – на генерации последующих токенов.
В основе механизма Внимание существует способность модели фокусироваться на определенных частях ввода в процессе генерации текста или в ходе обработки лингвистических задач. Этот процесс имеет решающее значение для обеспечения того, чтобы модель могла придать большую релевантность определенным словам или частям текста в зависимости от контекста.
L'вход о быстрый предоставляемый LLM на основе Transformer, делится – как мы также видели изначально – на последовательность токенов, которые могут быть словами, подмножествами слов или символов. Каждый входной токен затем выражается с помощью три пространства представления выдающийся: Запрос (К), Ключ (К) е Ценить (В). Квесты прогнозы они позволяют модели четко представлять значение токена (Q), его связь с другими токенами (K) и информацию, содержащуюся в самом токене (V).
Я «баллы активации” — это числовые значения, которые отражают релевантность данного ключа (Ключ) по конкретному запросу (Запрос). Сравнивая каждую пару, оценки активации позволяют нам установить, какой вес придать каждому соответствующему значению V.
Используя рассчитанные веса, модель затем вычисляет взвешенную комбинацию значений (V), соответствующих ключам (K), соответствующим каждому запросу (Q). Эта взвешенная комбинация представляет собой внимание, которое модель уделяет каждому элементу входных данных.
На последнем этапе «ценности внимания» объединяются для получения контекстное представление вводакоторый учитывает направленность модели на конкретные части быстрый такой же. И именно так могут лучшие LLM генерировать лингвистический вывод связный и содержательный.
Вступительное изображение предоставлено: iStock.com – Олемедиа
Программы для Windows, мобильные приложения, игры - ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале - Подписывайтесь:)





